File Robots.txt Là Gì? Kiến Thức Cơ Bản Về File Robots.txt
Trong thế giới rộng lớn của website và quản lý nội dung trực tuyến, việc hiểu rõ và sử dụng đúng công cụ là chìa khóa để tối ưu hóa trải nghiệm người dùng và tăng cường hiệu suất của trang web. Trong số những công cụ quan trọng, file robots.txt nổi lên như một phần không thể thiếu, đóng vai trò quyết định trong việc tương tác giữa trang web và các máy tìm kiếm. Bài viết này của IT Vũng Tàu sẽ giải đáp cho bạn về File Robots.txt là gì? và kiến thức cơ bản về file robots.txt, giúp bạn hiểu rõ về vai trò quan trọng của nó trong quá trình quản lý website và tối ưu hóa vị trí của trang web trên các công cụ tìm kiếm hàng đầu.

File Robots.txt Là Gì? Kiến Thức Cơ Bản Về File Robots.txt
Nội dung chính
- 1 File Robots.txt là gì?
- 1.1 Thuật ngữ phổ biến của File Robots.txt
- 1.2 Lợi ích khi tạo File Robots.txt
- 1.3 File Robots.txt có những hạn chế gì?
- 1.4 Cách hoạt động của File Robots.txt
- 1.5 Hướng dẫn cách kiểm tra File robots.txt cho Website
- 1.6 Một số quy tắc cần bổ sung vào File Robots.txt WordPress
- 1.7 Những lưu ý khi dùng File Robots.txt
- 1.8 Câu hỏi thường gặp về File Robots.txt
- 1.9 Kết luận
File Robots.txt là gì?
File robots.txt là một tệp văn bản đặc biệt được đặt trên máy chủ web để thông báo cho các robot tìm kiếm (như Googlebot của Google, Bingbot của Bing, và các robot tìm kiếm khác) về các phần của trang web họ có thể hoặc không thể “đọc” hoặc “cào” (crawling). Nó đóng vai trò quan trọng trong việc quản lý cách máy tìm kiếm tương tác với nội dung trên trang web của bạn.
File robots.txt giúp quản trị viên web kiểm soát quá trình index hóa của trang web, hạn chế quyền truy cập của các robot tìm kiếm vào các phần cụ thể của trang, và đảm bảo rằng những nội dung quan trọng hoặc nhạy cảm không bị hiển thị trong kết quả tìm kiếm. Mỗi trang web có thể có một file robots.txt riêng để tùy chỉnh quyền truy cập của robot tìm kiếm dựa trên nhu cầu cụ thể của nó.
Như vậy, file robots.txt đóng vai trò quan trọng trong chiến lược SEO (tối ưu hóa công cụ tìm kiếm) và giúp cải thiện hiệu suất của trang web trên các công cụ tìm kiếm hàng đầu.
Thuật ngữ phổ biến của File Robots.txt
Khi bạn làm việc với file robots.txt, có một số thuật ngữ phổ biến mà bạn cần hiểu để tận dụng tối đa khả năng của nó. Dưới đây là một số thuật ngữ quan trọng:
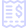
- User-agent: Đây là tên của robot tìm kiếm cụ thể mà bạn muốn áp dụng các quy tắc trong file robots.txt. Ví dụ, “Googlebot” là user-agent của Google.
- Disallow: Thuộc tính này chỉ định các phần của trang web mà bạn không muốn robot tìm kiếm truy cập. Đối với một phần cụ thể, bạn sẽ chỉ định đường dẫn sau Disallow, ví dụ:
Disallow: /private/. - Allow: Nếu bạn muốn cho phép robot tìm kiếm truy cập vào một phần cụ thể mà Disallow có thể đã ngăn chặn, bạn sử dụng thuộc tính Allow. Ví dụ:
Allow: /public/. - Crawl-delay: Xác định thời gian chờ giữa các yêu cầu của robot tìm kiếm đối với trang web của bạn. Điều này giúp kiểm soát lưu lượng và giảm áp lực lên máy chủ.
- Sitemap: Một liên kết đến sitemap của trang web. Sitemap là một tệp XML chứa danh sách các URL trên trang web, giúp robot tìm kiếm hiểu rõ cấu trúc và nội dung của trang web.
- Wildcard: Ký tự đặc biệt (*) được sử dụng để áp dụng quy tắc cho nhiều URL cùng một lúc. Ví dụ:
Disallow: /images/*.jpgsẽ ngăn chặn tất cả các ảnh định dạng JPG trong thư mục /images/.
Hiểu rõ những thuật ngữ này sẽ giúp bạn tạo và duy trì một file robots.txt hiệu quả cho trang web của mình.
Thuật ngữ phổ biến của File Robots.txt
Lợi ích khi tạo File Robots.txt
Việc tạo và duy trì một file robots.txt mang lại nhiều lợi ích quan trọng cho quản trị viên web và chiến lược SEO của trang web. Dưới đây là một số lợi ích chính:
- Kiểm Soát Truy Cập: File robots.txt cho phép bạn kiểm soát cách các robot tìm kiếm tương tác với trang web của bạn. Bạn có thể chỉ định những phần cụ thể mà bạn muốn chúng truy cập hoặc ngăn chặn chúng khỏi việc cào (crawling) những nội dung không mong muốn.
- Bảo Mật Thông Tin Nhạy Cảm: Nếu trang web của bạn chứa thông tin nhạy cảm hoặc không muốn xuất hiện trong kết quả tìm kiếm, bạn có thể sử dụng robots.txt để ngăn chặn robot tìm kiếm truy cập vào những phần này.
- Tối Ưu Hóa Hiệu Suất Crawl: Bằng cách hạn chế quyền truy cập vào những phần không quan trọng của trang web, bạn có thể tối ưu hóa hiệu suất cào của các robot tìm kiếm. Điều này có thể giảm áp lực lên máy chủ và tăng tốc độ index hóa trang web.
- Định Hình Index Trang Web: File robots.txt giúp định hình cách các công cụ tìm kiếm hiểu về cấu trúc của trang web. Bạn có thể chỉ định những phần quan trọng và ưu tiên để cải thiện vị trí trang web trong kết quả tìm kiếm.
- Tiết Kiệm Lưu Lượng: Bạn có thể sử dụng robots.txt để hạn chế tần suất cào của các robot tìm kiếm, giảm lưu lượng truy cập không cần thiết và tiết kiệm nguồn tài nguyên máy chủ.
- Ứng Dụng Các Chiến Lược SEO: File robots.txt là một phần quan trọng của chiến lược tối ưu hóa công cụ tìm kiếm (SEO). Bạn có thể tối ưu hóa trang web của mình để tăng cường khả năng xuất hiện trong kết quả tìm kiếm và thu hút lượng lớn người dùng hơn.
Tóm lại, việc sử dụng file robots.txt không chỉ giúp bảo vệ thông tin trang web mà còn là một công cụ quan trọng trong việc tối ưu hóa hiệu suất và vị trí của trang web trên các công cụ tìm kiếm.
File Robots.txt có những hạn chế gì?
Mặc dù file robots.txt là một công cụ hữu ích trong quản lý tương tác giữa trang web và robot tìm kiếm, nhưng cũng tồn tại một số hạn chế và điều cần lưu ý:
- Không Phải Là Phương Tiện Bảo Mật Chặt Chẽ: File robots.txt không phải là một biện pháp bảo mật chặt chẽ. Bất kỳ ai có thể xem nội dung của nó, và có một số robot tìm kiếm không tôn trọng hoặc bỏ qua file robots.txt.
- Không Ngăn Chặn Truy Cập Thực Sự: File robots.txt chỉ là một “hướng dẫn” cho robot tìm kiếm và không phải là một biện pháp ngăn chặn thực sự. Một số robot có thể bỏ qua các chỉ thị trong file này và tiếp tục cào nội dung mà bạn đã cố ngăn chặn.
- Không Bảo Vệ Quyền Riêng Tư Tuyệt Đối: File robots.txt không đảm bảo an ninh hoặc quyền riêng tư tuyệt đối cho nội dung trang web. Mặc dù nó có thể giúp ẩn những phần nhất định, nhưng không nên sử dụng nó như một phương tiện chính để bảo vệ thông tin nhạy cảm.
- Chỉ Ứng Dụng Cho Robot Tìm Kiếm Có Tôn Trọng: File robots.txt chỉ có tác dụng đối với các robot tìm kiếm mà tuân thủ và tôn trọng nó. Các robot không tôn trọng robots.txt hoặc không theo tiêu chuẩn của nó có thể không chấp nhận các hạn chế được đặt ra.
- Khả Năng Gây Nhầm Lẫn: Nếu không cấu hình đúng, file robots.txt có thể gây nhầm lẫn và dẫn đến việc các phần quan trọng của trang web không được index hóa bởi các robot tìm kiếm.
- Không Phải Là Giải Pháp Toàn Diện Cho SEO: File robots.txt chỉ là một phần của chiến lược SEO và không thể thay thế các biện pháp khác như sử dụng thẻ meta robots hoặc sitemap.
Mặc dù file robots.txt có nhiều ưu điểm, nhưng cũng cần lưu ý đến những hạn chế này và sử dụng nó một cách cẩn thận để đạt được kết quả mong muốn.
Cách hoạt động của File Robots.txt
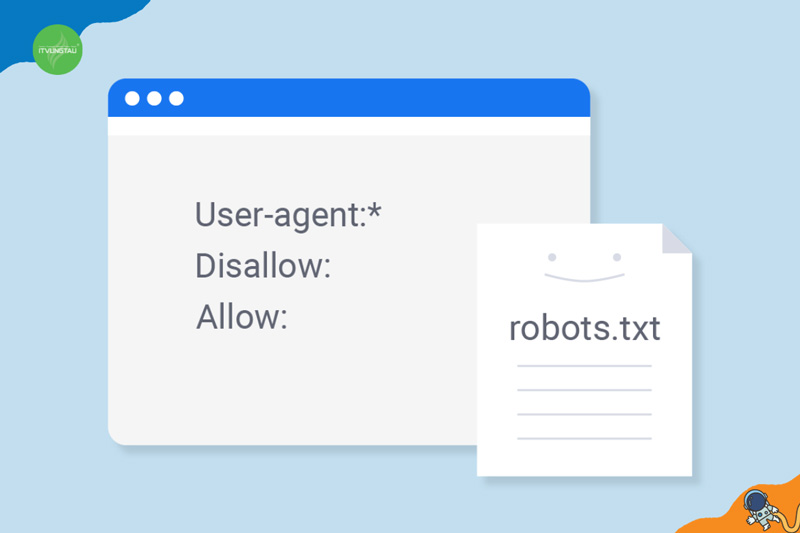
File robots.txt hoạt động như một “bảng hướng dẫn” cho các robot tìm kiếm, cung cấp hướng dẫn cho chúng về cách tương tác với trang web của bạn. Dưới đây là cách file robots.txt hoạt động:
- Các Robot Tìm Kiếm Đọc File Robots.txt: Khi robot tìm kiếm truy cập trang web của bạn, trước hết, chúng sẽ kiểm tra xem có file robots.txt không. File này thường được đặt ở gốc trang web (ví dụ: www.itvungtau.com/robots.txt).
- Phân Tích Nội Dung: Robot tìm kiếm sẽ đọc nội dung của file robots.txt để hiểu rõ các chỉ thị được cung cấp bởi trang web. Các chỉ thị này mô tả cụ thể về cách mà robot tìm kiếm nên xử lý các phần khác nhau của trang web.
- Xác Định Quyền Truy Cập: Dựa trên nội dung của file robots.txt, robot tìm kiếm sẽ xác định quyền truy cập của mình đối với từng phần của trang web. Chúng có thể quyết định cào (crawling) hoặc không cào (không crawling) những đường dẫn cụ thể.
- Thực Hiện Theo Chỉ Thị Disallow và Allow: Hai chỉ thị chính trong file robots.txt là Disallow và Allow. Chỉ thị Disallow chỉ định các phần mà robot tìm kiếm không nên cào, trong khi chỉ thị Allow có thể mở rộng quyền truy cập vào những phần được chỉ định.
- Thực Hiện Crawl Theo Cấu Hình: Robot tìm kiếm thực hiện crawl dựa trên các chỉ thị trong file robots.txt. Nếu có chỉ thị Disallow, chúng sẽ tránh cào các phần được đặt cấm. Nếu có chỉ thị Allow, chúng có thể tiếp tục cào các phần được phép.
Lưu ý rằng file robots.txt không phải là một biện pháp bảo mật mạnh mẽ và chỉ hoạt động với các robot tìm kiếm tôn trọng và tuân thủ nó. Một số robot có thể không quan tâm đến file này và tiếp tục cào trang web mà không tuân thủ các chỉ thị.
Cách hoạt động của File Robots.txt
Hướng dẫn cách kiểm tra File robots.txt cho Website
Kiểm tra file robots.txt cho một trang web có thể thực hiện dễ dàng bằng cách sử dụng trình duyệt web hoặc các công cụ trực tuyến. Dưới đây là một số cách bạn có thể kiểm tra file robots.txt:
Sử dụng Trình Duyệt Web:
- Trực Tiếp Truy Cập URL:
- Mở trình duyệt web và nhập địa chỉ trang web bạn muốn kiểm tra.
- Gắn thêm “/robots.txt” vào cuối URL (ví dụ: www
.itvungtau.com/robots.txt). - Nhập URL mới vào thanh địa chỉ và nhấn Enter.
- Sử Dụng Cú Pháp
site:trên Google:- Mở trình duyệt và nhập
site:itvungtau.com/robots.txtvào ô tìm kiếm của Google. - Nhấn Enter. Kết quả tìm kiếm sẽ hiển thị nội dung của file robots.txt của trang web.
- Mở trình duyệt và nhập
Sử Dụng Công Cụ Trực Tuyến:
- Google Search Console:
- Đăng nhập vào tài khoản Google Search Console.
- Chọn trang web bạn muốn kiểm tra.
- Trong mục “Crawl” ở thanh bên trái, chọn “robots.txt Tester.” Ở đây, bạn có thể kiểm tra và kiểm soát file robots.txt của trang web.
- Công Cụ Kiểm Tra Robots.txt Trực Tuyến:
- Có nhiều công cụ trực tuyến giúp bạn kiểm tra file robots.txt. Một số ví dụ bao gồm
https://www.google.com/webmasters/tools/robots-testing-toolhoặchttps://technicalseo.com/seo-tools/robots-txt/. - Truy cập một trong các công cụ này, nhập URL của trang web cần kiểm tra, và công cụ sẽ hiển thị nội dung của file robots.txt.
- Có nhiều công cụ trực tuyến giúp bạn kiểm tra file robots.txt. Một số ví dụ bao gồm
- Sử Dụng Command Line hoặc Terminal:
- Mở Command Prompt trên Windows hoặc Terminal trên macOS/Linux.
- Sử dụng lệnh curl hoặc wget để tải nội dung của file robots.txt. Ví dụ:
curl www.itvungtau.com/robots.txthoặcwget -O - www.itvungtau.com/robots.txt.
Bằng cách này, bạn có thể kiểm tra nhanh chóng nội dung của file robots.txt để đảm bảo rằng các chỉ thị được cấu hình chính xác và phản ánh đúng chiến lược SEO của trang web.
Một số quy tắc cần bổ sung vào File Robots.txt WordPress
Việc cấu hình file robots.txt cho trang web WordPress có thể giúp bạn kiểm soát cách các robot tìm kiếm tương tác với nội dung của trang web. Dưới đây là một số quy tắc bạn có thể bổ sung vào file robots.txt của WordPress:
1. Ngăn Chặn Các Thư Mục Không Cần Thiết:
Disallow: /wp-admin/Disallow: /wp-includes/Disallow: /wp-content/plugins/Disallow: /wp-content/themes/
Những quy tắc trên sẽ ngăn chặn robot tìm kiếm truy cập vào các thư mục quan trọng như trang quản trị (/wp-admin/), các tệp hệ thống (/wp-includes/), và các thư mục plugin và theme.
2. Ngăn Chặn Trang Phiên Bản:
Disallow: /?s=Disallow: /search/Disallow: /*?*
Những quy tắc này giúp ngăn chặn việc index hóa các trang tìm kiếm và tránh duplicate content thông qua các phiên bản URL khác nhau.
3. Ngăn Chặn Trang Phiên Bản Feed:
Disallow: /feed/Disallow: /comments/feed/
Nếu bạn không muốn các trang feed của blog của mình được index hóa, bạn có thể sử dụng quy tắc trên.
4. Ngăn Chặn Trang Tìm Kiếm Tạm Thời:
User-agent: *
Disallow: /*?
Quy tắc này có thể được sử dụng để tạm thời ngăn chặn việc index hóa các trang có chứa dấu ? trong URL. Hãy chắc chắn kiểm tra các ảnh hưởng trước khi triển khai.
5. Sitemap:
Sitemap: https://www.example.com/sitemap.xml
Bổ sung đường dẫn đến sitemap của trang web giúp các robot tìm kiếm hiểu cấu trúc trang web của bạn một cách hiệu quả.
Lưu Ý:
- Trước khi thêm hoặc thay đổi quy tắc trong file robots.txt, hãy đảm bảo bạn hiểu rõ tác động của chúng đối với trang web của bạn.
- Luôn kiểm tra các tác động SEO và đảm bảo rằng bạn không ngăn chặn các trang quan trọng khỏi việc index hóa.
- Kiểm tra file robots.txt thường xuyên để đảm bảo rằng nó phản ánh chiến lược tối ưu hóa của bạn.

Một số quy tắc cần bổ sung vào File Robots.txt WordPress
Những lưu ý khi dùng File Robots.txt
Khi sử dụng file robots.txt để quản lý cách các robot tìm kiếm tương tác với trang web của bạn, có một số lưu ý quan trọng cần xem xét:
- Thận Trọng Khi Ngăn Chặn Truy Cập:
- Đảm bảo rằng bạn hiểu rõ tác động của việc ngăn chặn truy cập vào các phần cụ thể của trang web. Việc ngăn chặn quá nhiều có thể ảnh hưởng đến hiệu suất SEO của trang web.
- Kiểm Tra Các Tác Động SEO:
- Trước khi thêm hoặc thay đổi quy tắc trong file robots.txt, hãy kiểm tra kỹ lưỡng các tác động SEO của chúng. Đôi khi, một chỉ thị có thể ngăn chặn các trang quan trọng khỏi việc index hóa.
- Kiểm Tra File Regularly:
- Kiểm tra file robots.txt thường xuyên để đảm bảo rằng nó phản ánh đúng chiến lược SEO và cấu trúc trang web hiện tại của bạn.
- Kiểm Soát Truy Cập Cẩn Thận:
- Đối với các phần quan trọng của trang web, hãy sử dụng “Disallow” cẩn thận. Nếu có sự cần thiết, hãy sử dụng “Allow” để mở rộng quyền truy cập.
- Kiểm Tra Thông Tin Nhạy Cảm:
- Tránh để thông tin nhạy cảm xuất hiện trong file robots.txt vì nó không phải là một biện pháp bảo mật chặt chẽ và có thể bị truy cập bởi ai đó có ý định xấu.
- Kiểm Tra Sitemap:
- Đảm bảo rằng bạn đã bổ sung đường dẫn đến sitemap của trang web vào file robots.txt để giúp các robot tìm kiếm hiểu cấu trúc trang web của bạn.
- Chấp Nhận Các Robot Tìm Kiếm:
- Một số robot không tôn trọng hoặc bỏ qua file robots.txt. Do đó, không nên dựa quá nhiều vào file này để bảo vệ nội dung nhạy cảm.
- Sử Dụng Wildcards Cẩn Thận:
- Nếu bạn sử dụng wildcards (ví dụ:
Disallow: /*?), hãy làm điều này cẩn thận vì nó có thể ảnh hưởng đến nhiều phần của trang web.
- Nếu bạn sử dụng wildcards (ví dụ:
- Kiểm Tra Bằng Công Cụ Google Search Console:
- Sử dụng Google Search Console để kiểm tra và xác nhận rằng các robot tìm kiếm đang hiểu và tuân thủ file robots.txt của bạn.
- Thực Hiện Kiểm Thử Khi Thay Đổi:
- Trước khi triển khai bất kỳ thay đổi nào trong file robots.txt, hãy thực hiện kiểm thử để đảm bảo rằng mọi thứ hoạt động đúng như mong đợi.
Bằng cách duy trì và sử dụng file robots.txt một cách cẩn thận, bạn có thể tối ưu hóa cách trang web của bạn tương tác với các công cụ tìm kiếm và bảo vệ thông tin quan trọng.
Câu hỏi thường gặp về File Robots.txt
Dưới đây là một số câu hỏi thường gặp liên quan đến file robots.txt:
- Robots.txt là gì?
- Trả lời: File robots.txt là một tệp văn bản đặc biệt được đặt trên máy chủ web để chỉ định cách các robot tìm kiếm nên tương tác với nội dung của trang web.
- Làm thế nào để tạo một file robots.txt?
- Trả lời: Bạn có thể tạo file robots.txt bằng cách sử dụng bất kỳ trình soạn thảo văn bản nào và lưu tệp với tên là “robots.txt” sau đó đặt tại thư mục gốc của trang web.
- Đường dẫn mặc định của file robots.txt là gì?
- Trả lời: Đường dẫn mặc định của file robots.txt là
www.example.com/robots.txt, trong đówww.example.comlà địa chỉ của trang web.
- Trả lời: Đường dẫn mặc định của file robots.txt là
- Làm thế nào để kiểm tra nội dung của file robots.txt?
- Trả lời: Bạn có thể kiểm tra nội dung của file robots.txt bằng cách thêm
/robots.txtvào cuối URL của trang web hoặc sử dụng công cụ Google Search Console.
- Trả lời: Bạn có thể kiểm tra nội dung của file robots.txt bằng cách thêm
- Quy tắc “Disallow” có ý nghĩa gì?
- Trả lời: Quy tắc “Disallow” trong file robots.txt được sử dụng để ngăn chặn robot tìm kiếm truy cập vào các phần cụ thể của trang web.
- Quy tắc “Allow” làm gì?
- Trả lời: Quy tắc “Allow” mở rộng quyền truy cập vào các phần cụ thể của trang web, đối với robot tìm kiếm nếu có quy tắc “Disallow” trước đó.
- Wildcards trong file robots.txt là gì?
- Trả lời: Wildcards (ký tự đặc biệt như
*) được sử dụng để áp dụng quy tắc cho nhiều URL cùng một lúc. Ví dụ:Disallow: /images/*.jpg.
- Trả lời: Wildcards (ký tự đặc biệt như
- File robots.txt có tác dụng như một biện pháp bảo mật không?
- Trả lời: Không, file robots.txt không phải là một biện pháp bảo mật mạnh mẽ. Nó chỉ là một “hướng dẫn” cho robot tìm kiếm và có thể bị bỏ qua bởi các robot không tôn trọng.
- Có cần thiết phải có file robots.txt cho mọi trang web không?
- Trả lời: Không, không bắt buộc phải có file robots.txt. Tuy nhiên, nó có thể là một công cụ hữu ích để kiểm soát cách robot tìm kiếm tương tác với trang web của bạn.
- Làm thế nào để kiểm tra xem file robots.txt có hiệu lực không?
- Trả lời: Bạn có thể sử dụng công cụ Google Search Console để kiểm tra cách robot tìm kiếm hiểu và tuân thủ file robots.txt của bạn.
Kết luận
File robots.txt không chỉ là một thành phần quan trọng trong quản lý tương tác giữa trang web và các robot tìm kiếm, mà còn là một công cụ quyết định trong chiến lược tối ưu hóa công cụ tìm kiếm. Việc hiểu rõ và chủ động cấu hình file này giúp quản trị viên web kiểm soát truy cập, bảo vệ thông tin nhạy cảm, và tối ưu hóa vị trí trang web trên các công cụ tìm kiếm hàng đầu.
Tuy nhiên, điều quan trọng là sử dụng file robots.txt một cách cẩn thận và hiểu rõ tác động của từng quy tắc. Lưu ý rằng nó không phải là một biện pháp bảo mật toàn diện và có thể bị bỏ qua bởi các robot không tuân thủ. Đồng thời, việc thường xuyên kiểm tra và điều chỉnh nó theo thời gian là quan trọng để đảm bảo rằng nó phản ánh chính xác chiến lược SEO và cấu trúc trang web của bạn.
Nhìn chung, file robots.txt đóng vai trò quan trọng trong việc duy trì sự ổn định và hiệu suất của trang web trước sự tác động của các công cụ tìm kiếm, giúp tối ưu hóa trải nghiệm người dùng và cải thiện vị trí của trang web trên Internet rộng lớn.
Thiết Kế Web Vũng Tàu
ITVUNGTAU là đơn vị chuyên thiết kế web tại Vũng Tàu và tỉnh Bà Rịa Vũng Tàu. Website theo yêu cầu với giao diện theo nhận diện thương hiệu, website theo mẫu giá rẻ với hàng nghìn mẫu website bán hàng, website giới thiệu sản phẩm, dịch vụ. Thiết kế website giá rẻ, Website đầy đủ tính năng và phù hợp với từng doanh nghiệp.Với tiêu chí vì khách hàng - hướng tới khách hàng, ITVUNGTAU mang đến những giải pháp toàn diện cho website của bạn: Thiết kế web theo hành vi khách hàng, website tương tác và trải nghiệm người dùng Website chuẩn SEO, tối ưu mã nguồn, các thẻ H, title, keywork, description,... Tương thích với mọi thiết bị di động Cập nhật công nghệ mới nhất, nén trang, bảo mật cao HOTLINE: 096 3636 138
Recommended Posts

Cấu Hình Gửi Nhận Email Theo Tên Miền Trên Điện Thoại IOS
3 Tháng Một, 2024
Cách Cấu Hình Email Theo Tên Miền Trên Điện Thoại Android – I
3 Tháng Một, 2024

Layout Website Là Gì? Kiến Thức Cơ Bản Về Layout Website
20 Tháng Mười Hai, 2023
-

TƯ VẤN TRỰC TIẾP
093 3636 138